What is OCR-A FONT?
During image conversion this font uses plain, thick strokes to shape familiar characters. It has a fixed width (monospaced); the printer is required to leave glyphs at a distance of 0.10 inch (0.254 cm) from each other. The reader must allow any spacing between 0.09 inch (0.2286 cm) and 0.18 inch (0.4572 cm)
Standardization
The American National Standards Institute (ANSI) standardized the OCR-A font as X3.4-1977. It later became the INCITS and the OCR-A standard is presently known as ISO 1073-1:1976. In addition to this, the German standard is called DIN 66008.
OCR-A: Development and Implementation:
1968: The American Type Founders developed the first Optical Character Recognition typface, terming it OCR-A.

Figure 1 - The OCR-A font example
Tor Lillqvist utilized MetaFont to illustrate the OCR-A font. His definition was later enhanced by Richard B Wales.
2004: John Sauter used font editors like Potrace and FontForge, converting the MetaFont definitions to TrueType (outline font standard developed by Apple). In 2007, Gürkan Sengün built on this implementation and created a package for the Debian Operating system.

Figure 2 -True type example by John Sauter
2008: Luc Devroye fixed the name of lower case z and rectified the vertical arrangement in John Sauter's implementation. 2006: Matthew Skala completed his independent project on Optical Character Recognition by converting the Metafont definitions to TrueType format. 2011: Skala developed and released a new version, produced by recalibrating the Metafont definitions. Matthew succeeded in making it compatible with METATYPE1 by creating outlines directly, without an intermediary tracing step.

Figure 3 - Truetype font example by Matthew Skala
Code Points:
A font is nothing but a set of glyphs or character shapes. Each glyph should be allotted a code point in a set of characters, thereby allowing a computer to use the font. The American Standard Code for Information Interchange (ASCII) was the customary character coding used when OCR-A was being standardized. All the glyphs of OCR-A did not fit into ASCII and five of the characters needed alternate glyphs. Unicode, also called ISO 10646, is the recent edition of ASCII. It enjoys special prerequisites for Optical Character Recognition characters. Several implementations of OCR-A look up to Unicode for assistance on character code assignments.
Space, numerals, and unaccented letters:
Every TrueType implementation of OCR-A font uses U+0030 through U+0039 for decimal numerals, U+0020 for space, U+0041 through U+005A for unaccented capital letters, and U+0061 through U+007A for unaccented small letters.
Apart from unaccented letters and numerals, most characters of OCR-A have conspicuous code points in ASCII. Many, if not all of OCR-A’s accented characters have clear code points.
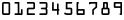
Figure 4 - OCR-A numerals

Figure 5 - OCR-A unaccented upper case letters
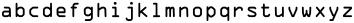
Figure 6 - OCR-A unaccented lower case letters
While Optical Character Recognition technology has progressed to a point where simple fonts are no longer necessary, the OCR-A font has still remained in use. Some people continue to prefer its unique style to any other font.