¿Qué es la fuente OCR-A?
Durante la conversión de imagen, esta fuente usa pinceladas planas y gruesas para formar caracteres familiares. Tiene un ancho fijo (monoespaciado); se requiere a la impresora dejar caracteres a una distancia de 0.10 pulgadas (0.254 cm) entre sí. El lector debe permitir cualquier espaciado entre 0.09 (0.2286 cm) pulgadas y 0.18 pulgadas (0.4572 cm).
Estandarización
El Instituto Americano de Estándares Nacionales (ANSI) estandarizó la fuente OCR-A como X3.4-1977. Luego, se convirtió en el INCITS, y el estándar OCR-A es actualmente conocido como ISO 1073-1:1976
Desarrollo e implementación de OCR-A
1968: El American Type Founders desarrolló la primera tipografía de Reconocimiento Óptico de Caracteres, denominándola OCR-A.

Figura 1 - Ejemplo de la fuente OCR-A.
Tor Lillqvist utilizó MetaFont para ilustrar la fuente OCR-A. Su definición fué luego mejorada por Richard B Wales.
2004: John Sauter utilizó editores de fuente como Potrace y FontForge, convirtiendo las definiciones MetaFont a TrueType (estándar de delineado de fuentes desarrollado por Apple). En 2007, Gürkan Sengün construyó sobre esta implementación y creó un paquete para el Sistema Operativo Debian.

Figura 2 - Ejemplo TrueType de John Sauter.
2008: Luc Devroye reparó el nombre de la z minúscula y corrigió la disposición vertical de la implementación de John Sauter. 2006: Matthew Skala completó su proyecto independiente en Reconocimiento Óptico de Caracteres convirtiendo las definiciones Metafont a formato TrueType. 2011: Skala desarrolló y publicó una nueva versión, producida recalibrando las definiciones Metafont. Matthew logró hacerla compatible con METATYPE1, creando delineados de forma directa, sin un paso de rastreo intermedio.

Figura 3 - Ejemplo de fuente TrueType de Matthew Skala
Puntos de código
Una fuente no es más que una serie de símbolos o formas de caractéres. A cada símbolo se le debe asignar un punto de código en un grupo de caracteres, permitiendo a una computadora usar la fuente. El Código Estandar Americano para Intercambio de Información (ASCII) fue el código de caracteres habitual usado durante la estandarización de OCR-A. Todos los símbolos de OCR-A no entraban en ASCII, y cinco de los caracteres necesitaban símbolos alternos. Unicode, también llamado ISO 10646, es la versión reciente de ASCII. Contiene prerequisitos especiales para caracteres OCR. Varias implementaciones de OCR-A averiguan la asignación de códigos de caracter en Unicode.
Espacios, numerales, y letras sin acentuación
Cada implementación TrueType de la fuente OCR-A usa U+0030 a U+0039 para números decimales, U+2000 para espacio, U+0041 a U+005A para letras mayúsculas sin acentuación y U+0061 a U+007A para letras minúsculas sin acentuación.
Fuera de las letras sin acento y numerales, la mayoría de los caracteres de OCR-A tienen puntos de código sobresalientes en ASCII. La mayoría, si no todos los caracteres acentuados de OCR-A tienen puntos de código claros.
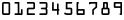
Figura 4 - Numeros OCR-A

Figura 5 - Caracteres sin acentuación en mayúscula de OCR-A
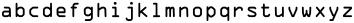
Figura 6 - Caracteres sin acentuación en minúscula de OCR-A
Si bien la tecnología OCR ha progresado a un punto en el que las fuentes simples ya no son necesarias, la fuente OCR-A continúa en uso. Algunas personas aún prefieren su estilo único al de cualquier otra fuente.